
在上一篇文章中,我們對於 Layer、Model、Module 的觀念做了摘要式的說明,同時在釐清其定義,並了解每一個主題的相關內容以及其用處。這次我們就要來了解這些內容,要如何呈現在程式碼中,並針對其做較深入的說明。同時,有關於前面常常提到「訓練」、「評估」等,具體到底是什麼?分別具有什麼內容與功能?都會在這章節呈現。
我們接下來就可以進入程式碼的部分了!我們會先從 Model 出發,而後擴大到說明整個 API 的結構。有關於建立 Model 之前要做哪些工作,可以直接參考【Day 04】的章節。
神經網路是在機器學習中最重要的腳色,而基本的神經網路,就是由好幾個節點與神經元所組成的 Layer 疊加而成,包含 Input Layer(輸入層)、Hidden Layer(隱藏層)、以及 Output Layer(輸出層)。
Keras 將這些深度學習的 API 建立在 TensorFlow 之上,讓我們可以用兩個很簡單的方式,就可以建立神經網路。建立這些神經網路的方式,最初有以下兩種:
顧名思義就是將 Layers 之間,以線性序列的結構呈現,每一層的輸出都會做為下一層的輸入,結構簡單易懂。

Sequential API 的 Model 區塊,可以用以下程式碼呈現,範例與說明如下:
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(units=128, activation='relu'))
model.add(Dense(units=10, activation='softmax'))
(1) 首先透過 Sequential() 方法來建立/定義序列模型
(2) 我們透過 model.add() 方法來加入 Layer。在此範例中我們放入了五個 Layer。有關每一個 Layer 的功能,可以參考上一篇文。最後的 Layer 就是輸出層。
(3) 輸出層之後就可以進入 Compile 編譯的程序了
相比於 Sequential API 來說,Functional API 就更加彈性了,因為我們可以透過簡單的方式定義 Model,也就是可以自己定義每一個 Layer 之間連接的關係。
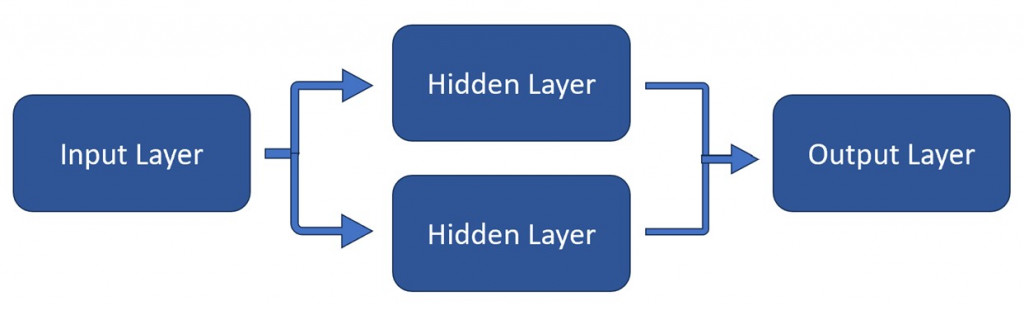
Functional API 的 Model 區塊,可以用以下程式碼呈現。以下我們用分析圖像的 Model 範例做說明:
input_layer = layers.Input(shape=(28, 28, 1))
conv1 = layers.Conv2D(32, (3, 3), activation='relu')(input_layer)
maxpool1 = layers.MaxPooling2D((2, 2))(conv1)
conv2 = layers.Conv2D(64, (3, 3), activation='relu')(maxpool1)
maxpool2 = layers.MaxPooling2D((2, 2))(conv2)
flatten_layer = layers.Flatten()(maxpool2)
dense1 = layers.Dense(128, activation='relu')(flatten_layer)
output_layer = layers.Dense(10, activation='softmax')(dense1)
model = models.Model(inputs=input_layer, outputs=output_layer)
(1) 首先我們直接定義 Model 的輸入層,做為圖像預處裡使用。
(2) 我們接下來便分別建立 Hidden Layer,包含了 Convolutional 與 Max-Pooling 的組合,再將該組合的輸出,再輸入進 Flatten Layer。
(3) 最後我們透過 Dense Layer 把資料一同彙集,做為輸出層。最後我們用 Model() 方法來定義整個 Model 的輸入層與輸出層。定義完成後,就可以進入 Compile 的階段了。
以上便是 Sequential 與 Functional API 再建立 Model 的主要程序。我們可以自行調整或定義 Layers 之間要如何組合。在完成建立 Model 之後,我們便會開始做編譯。編譯的時候會需要定義 Optimizer、Loss Function、以及 Metrics。我們會在下一個部分做說明
在我們對深度學習的結果作評估(Evaluate)時,我們需要對 Model 做編譯。編譯代表對模型的學習過程做佈署與調整,我們可以在其中自行定義 Optimizer(最佳化工具)、Loss Function(損失函數)、以及 Metrics(指標)。了解如何定義這些的內容看似很多,但其實我們只需要考量 資料類型、模型類型、以及期望的表現,就可以了解如何選擇 Optimizer、Loss Function、以及 Metrics 的演算法。
在上述決定好之後,就可以用 Compile() 方法完成編譯,其程式碼結構會用以下語法呈現,分述如下:
model.compile(optimizer='OPTIMIZER', loss='<LOSS FUNCTION>', metrics=['<METRIC>'])
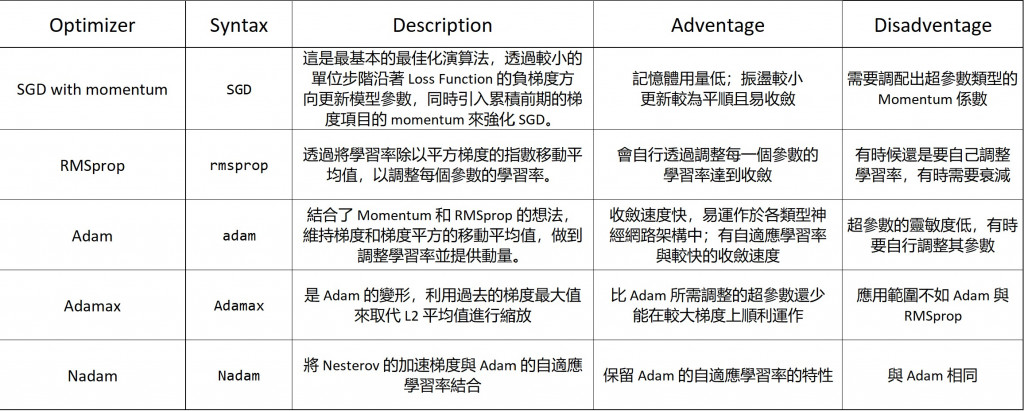
是一個透過更新 Model 的權重(weight)以達到損失函數最小值的演算法。以下列出幾個常用的 Optimizer 與其應用範圍
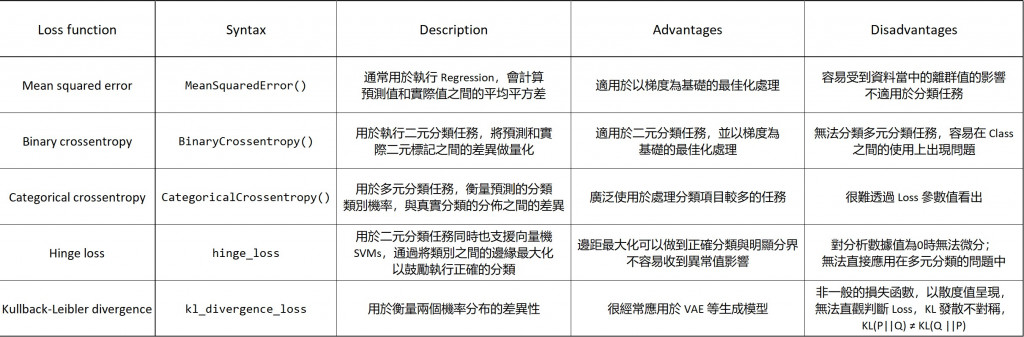
損失函數量測 model 在訓練資料中的表現,選擇損失函數時取決於你要分析與建立的 model 類型。常用的損失函數也有很多種類,分述如下:
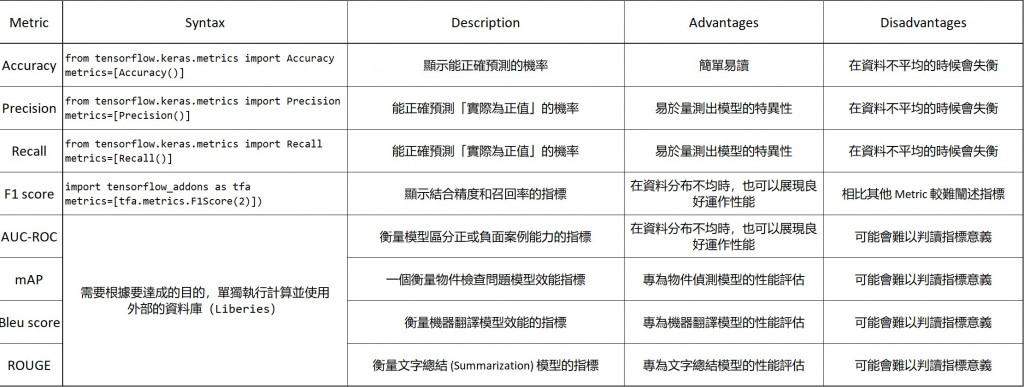
Metric 常用來評估模型在訓練與驗證資料的表現,選擇 Metric 時取決於你想要在模型中所得到的結論。常用的 Metric 也有很多種類,分述如下:
在資料訓練時,模型會將訓練資料分割成數個小區段後,在 model.fit() 裡面做訓練。其中訓練會進行 epoch(紀元、代)次數,而 Epoch 的次數是一個超參數,每一個 Epoch 都代表 x_train 與 y-train 都傳送入整個訓練的資料集。越多的 Epoch 代表訓練可以有更好的成效,但也可能會有 Overfitting 的風險。
model.fit(x_train, y_train, epochs=10)
我們也可以用驗證資料集(不同於測試集)來監測模型在訓練期間的表現,我們也可以透過這方式調整超參數,以避免 Overfitting 的現象產生。在程式碼中,我們首先設定了 train_test.split 的方式,將其中 20% 的訓練資料提取出來做驗證時使用
from sklearn.model_selection import train_test_split
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.2, random_state=42)
< #建立模型 >
< #編譯模型 >
在資料完成訓練後,我們就可以利用 history 參數來存取準確度與驗證資料的內容,這些資訊也能有像幫我們看出訓練的過程,以及找出發生 Overfitting 時的區段
history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val))
接下來就可以根據這些結果進入評估階段
在模型訓練之後,我們就可以用全新的一批測試資料集來評估模型的運作性能,並同時做預測,這也讓我們能看出模型是否存在對總體數據的準確評估或偏差,這同時也包含 Metric、Loss 或其他參考指標。
model.evaluate() 方法會取已做模型訓練後的測試資料,來計算 Loss 與 Metric 參數並回傳,分別儲存於前兩個被指定的參數中。
test_loss, test_accuracy = model.evaluate(x_test, y_test)
print('Test accuracy:', test_accuracy)
model.predict() 方法可以透過已做模型訓練後的測試資料,於全新的資料上做預測。預測的變數包含模型在每一筆 x_test 輸入時的輸出結果,我們便可以依據這些來決策模型是否能發行、或是仍需要修改。
predictions = model.predict(x_test)
print('Prediction:', prediction)
在模型完成訓練後,我們便可以將此模型存在電腦或其他外部記憶體中,以便日後存取使用。我們可以執行以下指令儲存。其中 <name_of_model> 就是檔案名稱;而 *.h5 就是副檔名。
model.save('<name_of_model>.h5')
在我們要載入模型時,只需要透過以下指令即可:
my_model = tf.keras.models.load_model('my_model.h5')
我們就可以在資料完成處理後,直接透過以上指令取代建立模型到訓練模型的部分,接下來僅需要進行新資料的評估與預測即可。
我們在編譯完成後,我們仍需要對模型做更深度的調整,才能持續滿足不同情境下的使用需求。我們可以透過以下三個方式來做調整,使模型在未來解決問題上更加實用。我們在日後的章節會再對此做更詳細的說明。
這表示在分析新的資料集、或是在不同的任務中要進一步針對「預訓練」模型做訓練的過程,一般都是調整其權重、超參數、以及增減 Layers 以適應於新的任務。我們也把這稱為遷移學習,利用上一個資料集所訓練的模型來解決類似的任務。
這是一個將多個機器學習模型的「預測區塊」做整個,以提升整體效能的技術。想像不同的模型都可能會捕捉不同的錯誤,所以將這些模型各司其職組合起來,可以讓模型預測上更加準確。
這代表我們調整出來的模型,已經有足夠高的準確率可以發行做使用時,我們便可以將這些模型整合到不同的應用程式、系統與服務當中,再依據這些用戶產生的新資料,反覆執行預測與決策的過程。
原本以為整理這些內容可以很快結案,結果在整理資料的過程中就花掉不少時間,但卻能釐清每一個環節要執行什麼程式、還有各種應用的方式。在下一篇文章,我們會討論另一個比起 Sequential 與 Functional Model 還更加活用的方式,稱為 Model Subclassing。這在自定義模型結構與模型訓練上提供了很大的靈活性,我們也可以藉此建構邏輯較為複查的模型。
[1] Sequential & Functional API
https://medium.com/analytics-vidhya/keras-model-sequential-api-vs-functional-api-fc1439a6fb10
[2] Codes of Paragraph 1 are referred from here
https://www.analyticsvidhya.com/blog/2021/07/understanding-sequential-vs-functional-api-in-keras/
[3] Understanding Keras Model Compilation, and Evaluation
https://saturncloud.io/blog/why-you-need-to-compile-your-keras-model-before-using-modelevaluate/#:~:text=In%20Keras%2C%20compiling%20the%20model,to%20minimize%20the%20loss%20function.
[4] Save and Load Models:
https://www.tensorflow.org/tutorials/keras/save_and_load
https://www.tensorflow.org/guide/keras/serialization_and_saving
[5] Fine-tuning the Model
https://www.tensorflow.org/tutorials/images/transfer_learning
[6] Ensembling
https://blog.paperspace.com/ensembling-neural-network-models/
[7] Deploying the Model (Paid Membership Only)
https://towardsdatascience.com/deploying-kaggle-solution-with-tensorflow-serving-part-1-of-2-803391c9648

 iThome鐵人賽
iThome鐵人賽